
Reinventing time reporting with modern .NET - part 1
It’s a wonderful time to be a .NET-developer. The .NET Core-team and so many others in the community is doing absolutely marvelous work reinventing the platform. As a web dev, I’m inundated with cool new toys to try out - many more than I can get around to: Pipe, Span<T>, Memory<T> for near-zero-allocation byte massaging; IHostedService for running background tasks along your website; typed HttpClient, SocketMessageHandler and Polly for making Http even more manageable; SignalR for real-time communication; Blazor for frontends in C#. I feel like a kid at Christmas.
In the spirit of reinvention, I’m going to rebuild an old hobby project of mine - time reporting for consultants - using all of the tools mentioned above. As most of the technologies are fairly new to me, there’s bound to be mistakes, bad practices and more in the code. If you see something, say something. The primary goal is to learn. :-)
The code for this project is available on GitHub.
The case & one solution
A major administrative pain for contractors (or maybe just me…) is tracking, reporting and invoicing time spent on projects. A multitude of solutions exist but somehow they seem to be just another layer of endless forms to fill out, making the process even more time-consuming. Of course, I might have missed the perfect tool for the job, so if you know of one - don’t tell me.
In a previous job we used Google Calendar events for tracking time. This had the advantage of having a very low barrier of entry since everybody was already using online calendars for managing their schedule. A perl script would then pull the iCal feeds when it was time to do invoicing or salary and parse them accordingly. I love how simple the solution is. No new software, very limited change of habits… I’m just not very skilled at perl. Never mind, we’re going to use the same basic principle but wrap it in beautiful modern .NET.
Table of contents
Since this is written as I go along it’s difficult to give an exact outline of what’s going to happen, but a preliminary table of contents looks like this:
- Overview and parsing: Basics of Pipe, Span<T>, Memory<T> and friends, along with some iCal nerdiness (this post).
- Asynchronicity and resilience: Using IHostedService to run background tasks, type HttpClient with the new SocketMessageHandler and Polly to make Http resilient.
- Building a real-time client: Building a front-end in Blazor and having it communicate with the server using SignalR. We’ll also add progress reporting from our background tasks.
Pipes for parsing
If you’ve never heard of pipes before, I suggest you take a few minutes to read up on David Fowler’s excellent introduction and Marc Gravell’s amazing in-depth series. In short, it’s streams on steroids: you get buffer management, partial reads, back-pressure & flow control, and first-class support for the new System.Memory APIs, meaning near-zero allocations. For our use case, our data sources are external. We’ll fetch the iCal-feeds from online calendar systems via Http or from files (during testing). Since we’re bringing them in from external sources (namely via HTTP) where data arrives when it arrives, we might benefit from processing them using the brand new System.IO.Pipelines APIs.
Getting a PipeReader from a stream is a one-liner:
var pipeReader = PipeReader.Create(stream, new StreamPipeReaderOptions(bufferSize: 4096));Voilá, we have ourselves a PipeReader, ready to feed us our iCal-feeds.
Be mindful of the buffersize: Setting it too low will kill performance as the reader will have to have to keep renting new memory.
Prior to .NET Core 3.0, we had to include the Pipelines.Sockets.Unofficial-package from Marc Gravell and the rest of the Stack Overflow team, and create the reader like so:
Do one thing and do it well
When I first wrote this post a year ago, Spans were new and the APIs very focused. With .NET Core 3.0 we’ve gotten a lot of very useful helpers. For our purposes, searching ReadOnlySequences has become a breeze thanks to the new SequenceReader class.
I’ve included it here, not so much to show how it’s done (you should read Steve Gordon’s introduction to SequenceReader for that) but to contrast what an immense improvement it is.
The .NET-team has chosen a very narrow focus for the System.Memory APIs which I applaud. With a change that propagates throughout the entire BCL, this becomes even more appropriate. Unfortunately for us, that means fewer convenience methods that we’ll have to implement ourselves - including searching.
Spans and Memory are abstractions over contiguous memory and searching here is easy - we have an IndexOf method just like we’re used to. Unfortunately, we don’t get Spans or Memorys from our Pipe, we get ReadOnlySequences. ReadOnlySequences are basically linked lists of Memory becoming an abstraction over disjoint pieces of memory. We can imagine how it works: Whenever new data comes in from the socket, it’s placed into a contiguous range of memory. As data comes in (but isn’t yet consumed) these pieces pile up, but while each individual piece is contiguous, we can’t be sure that they are lined up one after another in physical memory. I could get them all as a contiguous piece of memory, but it would require a copy. ReadOnlySequences gives me a close abstraction, but without the copy to a new contiguous piece of memory.
ReadOnlySequence has a method for finding specific content (.PositionOf), but it only accepts a single value. For our purposes, we need to find a multi-byte sequence (CRLF), so we’ll have to overload PositionOf and implement it ourselves. We won’t reinvent the wheel on this one, so if the sequence consists of only one segment, we’ll hand it of to the span.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static SequencePosition? PositionOf<T>(in this ReadOnlySequence<T> source, ReadOnlySpan<T> value) where T : IEquatable<T>
{
if (source.IsEmpty || value.IsEmpty)
return null;
if (source.IsSingleSegment)
{
var index = source.First.Span.IndexOf(value);
if (index > -1)
return source.GetPosition(index);
else
return null;
}
return PositionOfMultiSegment(source, value);
}However, if the sequence has many elements, it’s a whole other situation. We risk our needle crossing the boundaries of multiple segments, so we can’t just hand of the search. What we’ll do is search for the first element in our needle. If it matches, we’ll check each successive value by simply iteration, which our ReadOnlySequence is happy to help with.
public static SequencePosition? PositionOfMultiSegment<T>(in ReadOnlySequence<T> source, ReadOnlySpan<T> value) where T : IEquatable<T>
{
var firstVal = value[0];
SequencePosition position = source.Start;
SequencePosition result = position;
while (source.TryGet(ref position, out ReadOnlyMemory<T> memory))
{
var offset = 0;
while (offset < memory.Length)
{
var index = memory.Span.Slice(offset).IndexOf(firstVal);
if (index == -1)
break;
var candidatePos = source.GetPosition(index + offset, result);
if (source.MatchesFrom(value, candidatePos))
return candidatePos;
offset += index + 1;
}
if (position.GetObject() == null)
{
break;
}
result = position;
}
return null;
}
public static bool MatchesFrom<T>(in this ReadOnlySequence<T> source, ReadOnlySpan<T> value, SequencePosition? position = null) where T : IEquatable<T>
{
var slice = position == null ? source : source.Slice(position.Value);
if (slice.Length < value.Length)
return false;
var candidate = slice.Slice(0, value.Length);
int i = 0;
foreach (var sequence in candidate)
{
foreach (var entry in sequence.Span)
{
if (!entry.Equals(value[i++]))
return false;
}
}
return true;
}This is very much a hot path, so any and all optimizations are welcome - please let me know if you see something.
UPDATE: MatchesFrom previously had a bug caused by missing bounds checks. If you used it for anything, please update it.
Consuming the pipe
Now that we can search for sequences of bytes, we turn our attention to RFC 5545 - the iCal specification. We’re not interested in all of it. In fact, for our use case, we’re only interested in events, their title, time and duration, and who participated. We’ll setup a basic loop to look for events as data comes in.
public static async ValueTask GetEvents(PipeReader reader, Action<Event> callback, CancellationToken cancellationToken = default)
{
while (true)
{
// Tell the pipe we need more data.
// It will only return once it has new data we haven't seen.
// Unlike a stream the pipe will return bytes we've previously seen but not consumed.
var read = await reader.ReadAsync(cancellationToken);
if (read.IsCanceled) return;
var buffer = read.Buffer;
if (TryParseEvent(buffer, out Event nextEvent, out SequencePosition consumedTo))
{
// We explicitly tell the pipe that we've used a certain amount of bytes.
// The pipe will then release that memory back the pool from which it was rented.
reader.AdvanceTo(consumedTo);
callback(nextEvent);
continue;
}
// We didn't find what we're looking for.
// Signal the pipe that we've seen it all but only used some of it.
reader.AdvanceTo(consumedTo, buffer.End);
if (read.IsCompleted) return;
}
}From a consumer perspective, it looks a lot like a naive stream implementation - which is good, since it means it’s simple to reason about - but as Davids post show, there’s a lot going on under the covers. The main difference is that while a stream consumes data as part of reading it (unless you peek, which generally require an additional copy), you have to be explicit about it with pipes. When you read, you get all available data but nothing is discarded. Only once you call .AdvanceTo(), does the pipe discard data up to the position you specify.
Pipe introduces a new concept as part of its back pressure mechanism, which you can see play out in the second call to .AdvanceTo() (for the case where we didn’t find an entire Event). Here we tell the pipe that we’ve consumed data up to some position (in our case, up to the beginning of the BEGIN:VEVENT-tag) which can then be discarded and the memory recycled, but that we’ve examined all of the buffer. This tells the pipe that it shouldn’t return from a call to .ReadAsync() until it has new data. Even though it has unconsumed data, it should wait for more. No more spinning waits filling duplicate buffers. Fantastic!
Parsing iCal feeds
RFC 5545 is not to complicated. The file is made up of lines, which can “fold” (meaning we need to ignore certain sequences). Events are marked with start (“BEGIN:VEVENT”) and end tags (“END:VEVENT”), so we can search for those.
Unfortunately, we need to check that the linebreak isn’t followed by a space or tab, since these denote “folding” of lines, i.e. wrapping of lines. So yet another layer of loops and counting…
private static void ReadEvent(ReadOnlySequence<byte> payload, out Event nextEvent)
{
nextEvent = new Event();
// Loop through all the content lines and parse them.
var eof = false;
var linestart = 0L;
while (!eof)
{
// Find the next line
var offset = linestart;
SequencePosition? eol = null;
while (offset < payload.Length)
{
var remainder = payload.Slice(offset);
offset = payload.Length - remainder.Length;
eol = remainder.PositionOf(UTF8Constants.NewLine.Span);
if (eol == null)
{
// We're past the last line break and thus done!
eof = true;
return;
}
// We got a CRLF - check that it's not followed by a tab or a space.
var atCRLF = remainder.Slice(eol.Value);
if (atCRLF.Length > UTF8Constants.NewLine.Length)
{
var nextByte = atCRLF.Slice(UTF8Constants.NewLine.Length, 1).First.Span[0];
if (nextByte == UTF8Constants.Tab || nextByte == UTF8Constants.Space)
{
offset += payload.Length - atCRLF.Length + UTF8Constants.NewLine.Length + 1;
continue;
}
}
// Slice from start to line break
var line = payload.Slice(linestart, eol.Value);
TryParseLine(line, nextEvent);
// Read past the line break
linestart += line.Length + UTF8Constants.NewLine.Length;
break;
}
if (offset >= payload.Length)
break;
}
}Newbie tip: You can’t very easily translate a SequencePosition to an index, but if you are only slicing from the front, you can subtract the length of the result from the original in order to get the index. Took me a while to figure out.
With our line neatly cut out for us, we can split it according to RFC 5545. In particular, we need the syntax:
contentline = name *(";" param ) ":" value CRLFSince our interest is very limited, we won’t bother with parameters for now. If you want to expand on the code for your own use, you’d just create yet another loop looking for semi-colons. For now, we’ll find the first colon and take whatever comes after as the value, and the first semi-colon and whatever comes before as the property name. Then we’ll update our event accordingly.
private static bool TryParseLine(ReadOnlySequence<byte> buffer, Event nextEvent)
{
// Per RFC 5545 contentlines have the following syntax:
// contentline = name *(";" param ) ":" value CRLF
// meaning we'll read until ; or : and treat accordingly
var valueDelim = buffer.PositionOf(UTF8Constants.Colon);
if (valueDelim == null)
{
// The line is somehow invalid. Abort.
return false;
}
var nameAndParams = buffer.Slice(0, valueDelim.Value);
var value = buffer.Slice(valueDelim.Value).Slice(1);
// Check for parameters - for our use, we don't care about their values, so we simply ignore them.
var paramDelim = nameAndParams.PositionOf(UTF8Constants.Semicolon);
var name = paramDelim == null ? nameAndParams : nameAndParams.Slice(0, paramDelim.Value);
var parameters = paramDelim == null ? new ReadOnlySequence<byte>() : nameAndParams.Slice(paramDelim.Value).Slice(1);
UpdateProperty(name, parameters, value, nextEvent);
return true;
}
private static readonly InstantPattern iCalInstantPattern = InstantPattern.CreateWithInvariantCulture("uuuuMMdd'T'HHmmss'Z'");
private static void UpdateProperty(ReadOnlySequence<byte> name, ReadOnlySequence<byte> parameters, ReadOnlySequence<byte> value, Event nextEvent)
{
if (name.MatchesFrom(UTF8Constants.Attendee.Span))
{
nextEvent.Attendees.Add(value.ToString(Encoding.UTF8));
}
// Most properties left out for brevity.
}String creation
Only thing missing is the .ToString(Encoding encoding) overload above. Creating strings from ReadOnlySequences aren’t very easy and documentation is very sparse, so I added the extension method based on David Fowler’s article.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static string ToString(in this ReadOnlySequence<byte> buffer, Encoding encoding)
{
if (buffer.IsSingleSegment)
{
return encoding.GetString(buffer.First.Span);
}
return string.Create((int)buffer.Length, buffer, (span, sequence) =>
{
foreach (var segment in sequence)
{
encoding.GetChars(segment.Span, span);
span = span.Slice(segment.Length);
}
});
}Again, if the sequence consists of a single segment, we have built-in helpers doing all the work for us. If not, we’ll call the new String factory-method .Create() which decodes the byte stream directly into a pre-allocated span avoiding unnecessary allocations and copies.
Is it worth all the trouble?
We can parse the parts of the iCal feed that we are interested in and skip the rest, with (hopefully) very few allocations along the way. But is it worth it? The code is a bit more complex than it could have been, particularly considering that excellent libraries such as iCal.NET.
I’m going to compare the two using BenchmarkDotNet. It’s a decidedly apples-to-oranges comparison. iCal.NET is a fully RFC 5545-compliant library while what we’re doing here is very limited in scope. It is in no way transferable to anything but this specific use case, but in our particular situation where the choice is between the two, it makes sense.
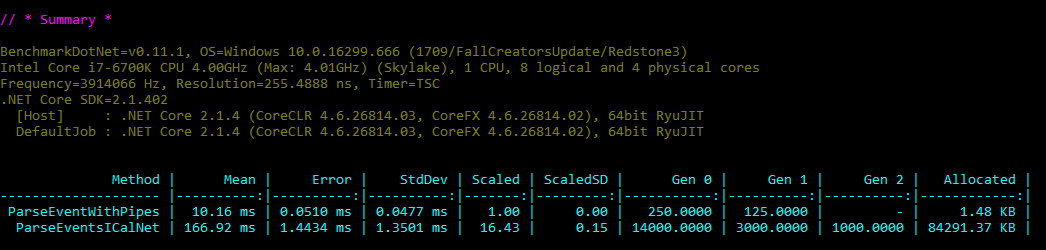
Benchmark.net output
So, roughly 16 times as fast and allocations almost eliminated compared to almost 82 MB and a lot of long-lived references. Nice!
Until next time
Thank you for sticking with me this far. If you’ve spotted any errors, poor design choices or other possibilities for improvement, please let me know by filing a pull request against this sites repo. I’ll expand the iCal-parser as needed for this series, but don’t expect it to ever match iCal.NET.
Next time we’ll build a asynchronous task runner using the IHostedService interface. We’ll also look at how simple it is to add connection resilience using Polly. Stay tuned!